With six Agile gene related switches (note, that we get Feature-driven plus Interactive-incremental automatically when we switch-off Waterfall) , this means that we could experiment with 26, or 64 different gene combinations. Moreover, each one of the genes can have a varying effect depending on the setting of that gene’s “sub-parameters. These sub-parameters are summarized below:
Micro-Optimization:
Improvement in FCC based on Sprints Completed, Improvement in Productivity based on Sprints Completed, and Improvement in Rework Discovery based on Sprints Completed are table functions that translate the number of sprints completed into a fractional improvement in three of the rework cycle’s controlling parameters.
Refactoring:
Technical Debt Accrued per Unit of Work, Effect of Technical Debt on FCC, and Refactoring Aggressiveness represent “how much technical debt is accumulating”, “what its effect on FCC is”, and “how proactive is the project in refactoring their software”.
Continuous Integration:
Here we employ several exogenous parameters that specify a) the cost of setting up continuous integration, b) the level of automation that is employed, and c) the effect of continuous integration on FCC and Rework Discovery. The variables are: Level of Automated Testing Used, CM and Build Environment Automation Level, Effect of Automated Testing on Rework Discovery, Effect of Automated Testing on Productivity, Effect of CM Environment on Rework Discovery, and Effect of CM Environment on Productivity.
Customer Involvement:
Here we have external parameters that dictate how much requirements changes (negative aspect) will result from customer involvement, as well as how their involvement will help rework discovery and reduce uncertainty. The variables are: Effect of Customer Involvement on Requirements Churn, Elimination of Requirements Uncertainty Based on Sprint Progress, and Improvement in Rework Discovery Due to Customer Involvement.
Team Dynamics:
Here we capture the effect of team meetings and pair programming on the rework cycle. The sub-parameter variables are: Effect of PP on FCC, Effect of PP on Experience Gain, Effect of PP on Productivity, Effect of Agile Teams on Pdy, Effect of Team Meetings on FCC, and Effect of Team Meetings on Rework Discovery.
These sub-parameters (some exogenous variables and some lookup table functions) have been modelled using conservative values and assumptions. We have performed our experiments without changing these parameters – doing so would have exponentially increased the complexity of our experiment, way beyond the 64 high level cases defined by the binary on/off variables employed in our simulations. Additional improvements in the model can include a second dashboard that allows experimentation with all of the sub-parameters.
Without calibrating or fine-tuning these sub-parameters, we cannot make any definitive claims about the ability of the model to reproduce the behaviour of a real project, nor can we use it for predictive purposes. Each of the seven genes has both reinforcing and balancing effects on the system, via direct or indirect impact on the key parameters of the project’s rework cycle, namely: Productivity, Effective Staff, Fraction Correct and Complete, Development Rework Discovery Rate. Some of the genes also have the potential of generating more tasks to be performed in either the Product Backlog or the Release Backlog.
Depending on the choice of sub-parameter values, each gene’s impact can be weighted one way or the other. To clarify this point, for example, as discussed earlier: pair programming lowers productivity, but improves quality. Depending on which of these two effects is more powerful, pair programming may or may not be a beneficial practice for project performance.
Nevertheless, the development of this model has provided insight into how these Agile Genes interact to produce project behaviour. This research has also generated considerable personal learning through experimentation with the model structure. In retrospect, the development of the model itself was an iterative and incremental process – the construction of each new portion of the model revealed new insights and learning about the inter-relationships between the different agile practices, and how they affect project performance.
Comparison of experiment results with personal experience
Experimentation with the APD has led to the understanding of some of the results from my personal experience with Agile. During the times when I have practiced some form of Agile development, I have never been in an environment where all seven of the Agile genes were employed.
In these environments within which I have practiced Agile, Customer Involvement was never truly practiced: in my case a System Engineer (SE) has played the role of customer proxy, and was either unwilling or unable to participate in daily scrums. Moreover, there is no guarantee that an SE could really represent the vision of the end user .
Continuous Integration was also not truly practiced in my experience: Although we employed automatic unit-testing, very little else was automated. Functional tests were still long and laborious procedure-driven tasks. Configuration Management policy was also isolationist: in other words, pieces of functionality were developed in isolation and only integrated (“merged”) near the end of the development cycle, thus no “continuous” aspect of integration to identify rework early.
Refactoring (at least, large-scale refactoring) is also a frowned-upon practice. It is considered by managers who do not understand the concept of Technical Debt to be extra non-value-added work. In one project (other than those I have mentioned previously) I found a massive amount of duplication in the C++ class hierarchy in various areas of the software. When I proceeded with a big refactoring effort, a senior engineering fellow was brought in by management to investigate my actions (as a sort of external technical auditor). Thankfully, he agreed with what I was doing and I moved on unscathed; however this is illustrative of the type of anti-refactoring sentiment in many large-scale software development communities. Likewise, I only had the opportunity to practice Pair Programming in the one case mentioned in section 1.2, otherwise this is also deemed as a productivity waste in large-scale software organizations.
This means that in most of my personal experiences with Agile, we were only able to employ elements of the Feature-Driven, Iterative-Incremental, and Micro-Optimizing genes. If we execute the APD model with the same base parameters, and only these genes activated, we get the following results:
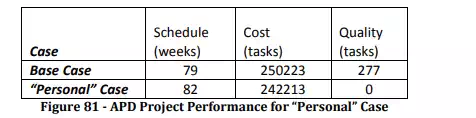
The results are identical to Case #2 discussed earlier during our experimentation. As we can see, this configuration saves some cost, improves quality, and yet delays the project by three weeks. This is by no means a win for agile over waterfall, or grounds to declare one superior to the other. Depending on program priorities, schedule may be the most important factor. However this explains a bit more about the promise and reality of agile practices.